
केवल 3 सेकंड में, एक एआई जिसने कभी आपको बोलते हुए नहीं सुना है वह आपकी आवाज की पूरी तरह से नकल कर सकता है। यह माइक्रोसॉफ्ट के आर्टिफिशियल इंटेलिजेंस - VALL-E टेक्स्ट-टू-स्पीच मॉडल की नवीनतम उपलब्धि है, जो केवल 3 सेकंड के भाषण के साथ किसी की भी आवाज को कॉपी कर सकता है।
Microsoft VALL-E केवल 3 सेकंड बोलने के बाद हमारी आवाज की नकल करेगा
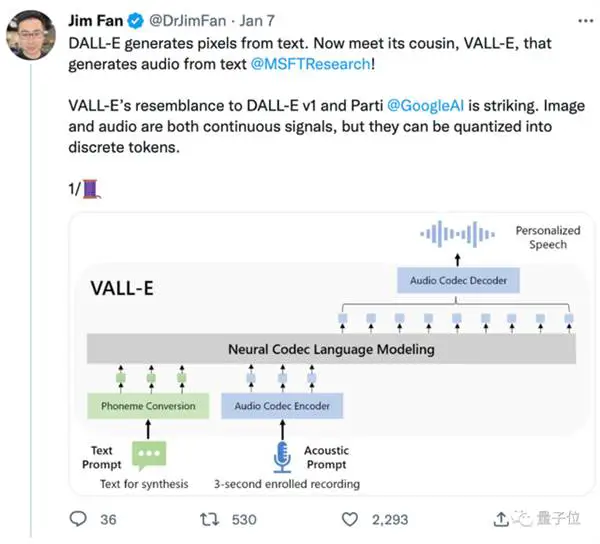
यह DALL E से उत्पन्न हुआ है, लेकिन ऑडियो क्षेत्र में माहिर है, और टेक्स्ट-टू-स्पीच प्रभाव ऑनलाइन जारी होने के बाद लोकप्रिय हो गया।
कुछ उपयोगकर्ताओं ने कहा कि यदि VALL·E और ChatGPT को मिला दिया जाए, तो परिणाम आश्चर्यजनक होगा। दूसरों के लिए, ऐसा लगता है कि वह दिन दूर नहीं है जब एआई के साथ वीडियो कॉल करना संभव होगा। ऐसे लोग भी हैं जो मजाक करते हैं कि एआई ने लेखकों और चित्रकारों का ख्याल रखने के बाद आवाज अभिनेता हैं।

लेकिन VALL·E 3 सेकंड में "अनसुनी" ध्वनि की नकल कैसे करता है?
VALL-E भाषा मॉडल के साथ ऑडियो का विश्लेषण करता है। यह एआई "अनसुनी" ध्वनियों के आधार पर भाषण को संश्लेषित करता है, अर्थात शून्य-नमूना शिक्षा।
पारंपरिक टेक्स्ट-टू-स्पीच समाधान मूल रूप से प्री-वर्कआउट मोड के साथ-साथ फाइन-ट्यूनिंग है। यदि शून्य नमूना परिदृश्य में उपयोग किया जाता है, तो इसका परिणाम उत्पन्न भाषण की समानता और स्वाभाविकता में कमी होगी।

इसके आधार पर, VALL-E पारंपरिक स्वर मॉडल की तुलना में एक अलग विचार का प्रस्ताव करते हुए कहीं से भी निकला।
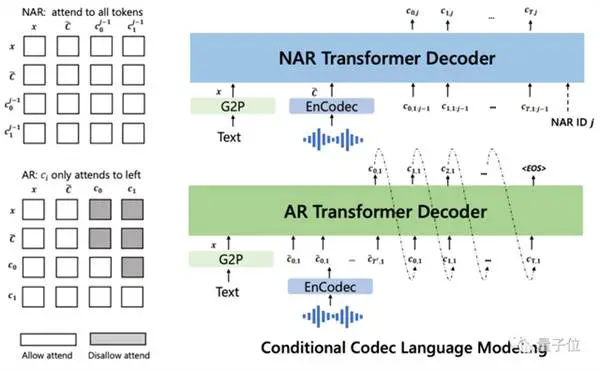
सुविधाओं को निकालने के लिए मेल स्पेक्ट्रम का उपयोग करने वाले पारंपरिक मॉडल की तुलना में, VALL-E भाषा मॉडल के कार्य के रूप में सीधे भाषण संश्लेषण लेता है, पूर्व निरंतर है और बाद वाला असतत है।
विशेष रूप से, पारंपरिक भाषण संश्लेषण प्रक्रिया अक्सर "फोनीमे → मेल-स्पेक्ट्रोग्राम (मेल-स्पेक्ट्रोग्राम) → तरंग" का मार्ग होती है।
लेकिन VALL -E ने इस प्रक्रिया को "स्वनिमे → असतत ऑडियो कोडिंग → तरंग" में बदल दिया:
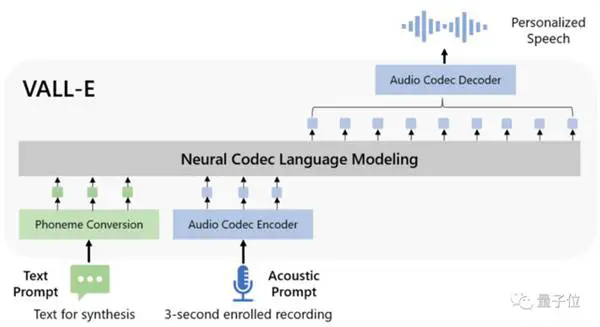
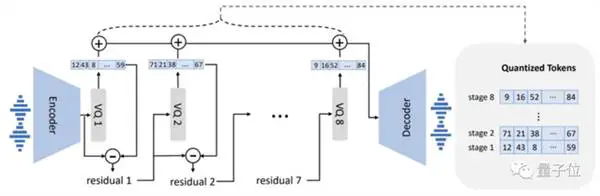
मॉडल डिजाइन के संदर्भ में, VALL-E भी VQVAE के समान है। असतत टोकन की एक श्रृंखला में ऑडियो की मात्रा निर्धारित करता है। पहला क्वांटाइज़र स्पीकर की ऑडियो सामग्री और पहचान विशेषताओं को कैप्चर करने के लिए ज़िम्मेदार है, जबकि दूसरा क्वांटाइज़र सिग्नल शोधन के लिए ज़िम्मेदार है। जो अधिक स्वाभाविक लगता है:
फिर पाठ और 3-सेकंड ऑडियो प्रॉम्प्ट द्वारा वातानुकूलित, यह स्वत: प्रतिगामी रूप से एक असतत ऑडियो एन्कोडिंग आउटपुट करता है:
लेकिन इतना ही नहीं, जीरो-सैंपल स्पीच सिंथेसिस के अलावा, VALL-E GPT-3 के साथ मिलकर वॉयस एडिटिंग और वॉयस कंटेंट क्रिएशन को भी सपोर्ट करता है।
परिवेश पृष्ठभूमि ध्वनि को भी पुनर्स्थापित किया जा सकता है
संश्लेषित मुखर प्रभावों को देखते हुए, VALL-E केवल वक्ता के समय से अधिक को पुनर्स्थापित कर सकता है।
न केवल मौके पर पिच की नकल की जाती है, बल्कि यह विभिन्न प्रकार की भाषण गति का भी समर्थन करती है। उदाहरण के लिए, ये VALL-E द्वारा प्रदान की जाने वाली दो अलग-अलग भाषण गति हैं जब एक ही वाक्य को दो बार बोला जाता है, लेकिन टोनल समानता अभी भी उच्च है:
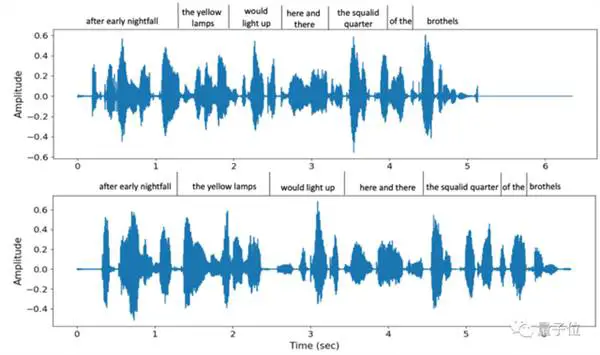
साथ ही, दूसरे पक्ष की पृष्ठभूमि परिवेश ध्वनि को भी सटीक रूप से पुनर्स्थापित किया जा सकता है।
इसके अतिरिक्त, VALL-E वक्ता की विभिन्न प्रकार की भावनाओं की नकल कर सकता है, जिसमें गुस्सा, नींद, तटस्थ, आनंद और मतली जैसे कई प्रकार शामिल हैं।
यह उल्लेखनीय है कि VALL·E प्रशिक्षण के लिए उपयोग किया जाने वाला डेटा सेट विशेष रूप से बड़ा नहीं है।
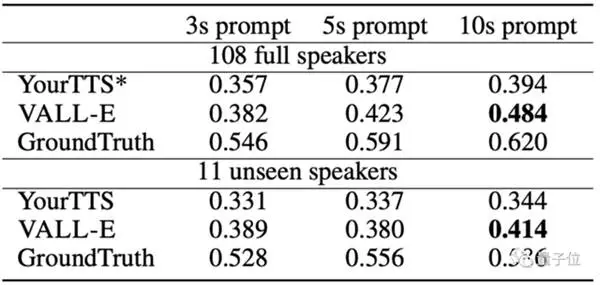
OpenAI के व्हिस्पर की तुलना में, जिसके लिए 680.000 ऑडियो प्रशिक्षण घंटों की आवश्यकता होती है और केवल 7.000 से अधिक वक्ताओं और 60.000 प्रशिक्षण घंटों का उपयोग किया जाता है, VALL-E मॉडल YourTTS टेक्स्ट-टू-स्पीच की समानता के मामले में पूर्व-प्रशिक्षित टेक्स्ट-टू-स्पीच से आगे निकल गया।
इसके अलावा, YourTTS ने प्रशिक्षण के दौरान 97 में से 108 वक्ताओं की आवाज पहले ही सुन ली थी, लेकिन वास्तविक परीक्षण में यह अभी भी VALL-E से कम है।
जिन क्षेत्रों में इसे लागू किया जा सकता है:
इसका उपयोग न केवल आपकी स्वयं की आवाज की नकल करने के लिए किया जा सकता है, जैसे विकलांग लोगों को दूसरों के साथ बातचीत पूरी करने में मदद करना, बल्कि जब आप नहीं चाहते हैं तो आप इसका उपयोग अपने लिए बोलने के लिए भी कर सकते हैं। बेशक, इसका उपयोग ऑडियो बुक रिकॉर्डिंग के लिए भी किया जा सकता है।
हालांकि, VALL-E अभी तक ओपन सोर्स नहीं है और आपको इसे आजमाने के लिए कुछ और इंतजार करना पड़ सकता है।
अमेज़न पर ऑफर पर







